판매자센터의 상품등록 페이지에는 브랜드를 선택하는 모달이 있습니다.
상품을 등록하려면 반드시 거쳐야 하는 필수 단계인데, 골프 이커머스 서비스라 브랜드 종류가 수백 개에 달하고, 전체 브랜드를 알파벳 순으로 노출하면서 검색과 알파벳 필터 기능까지 함께 제공하고 있어요.
그런데 이 모달에 계속 마음에 걸리는 부분이 하나 있었어요. 입력창을 눌러도 모달이 바로 열리지 않고, 한 박자 늦게 뜨는 느낌이 드는 겁니다.
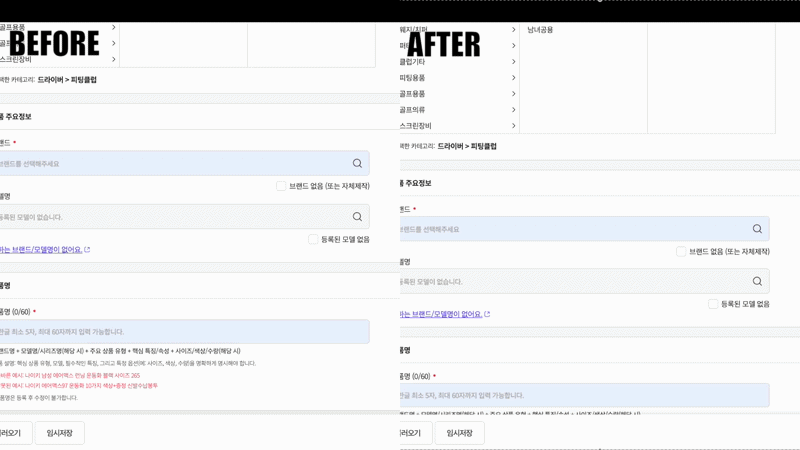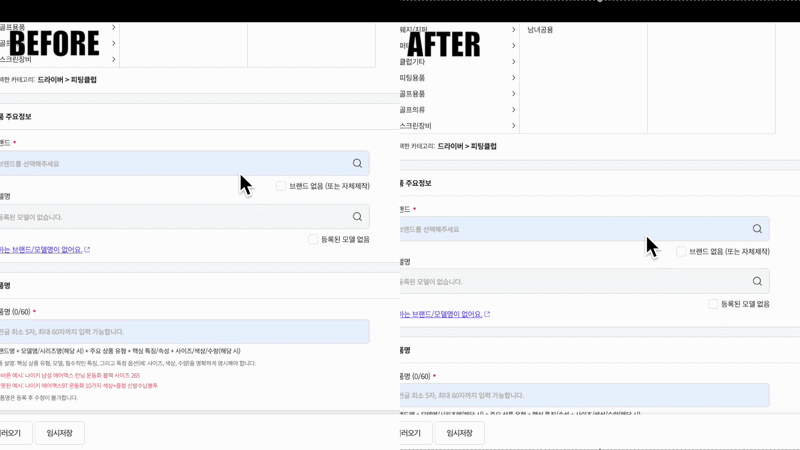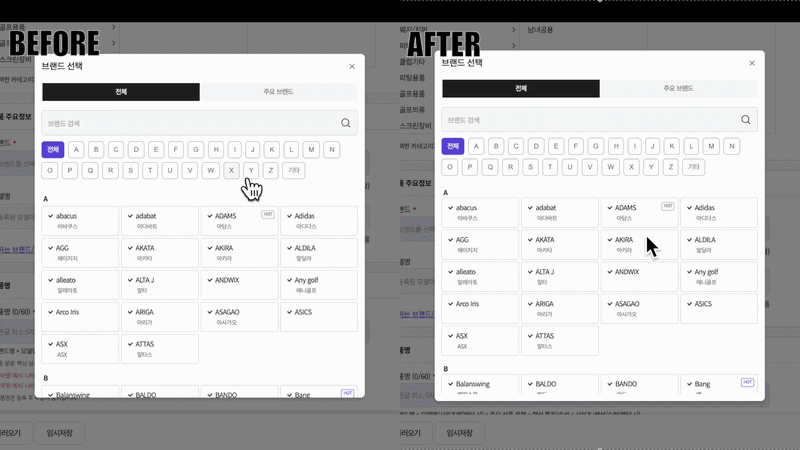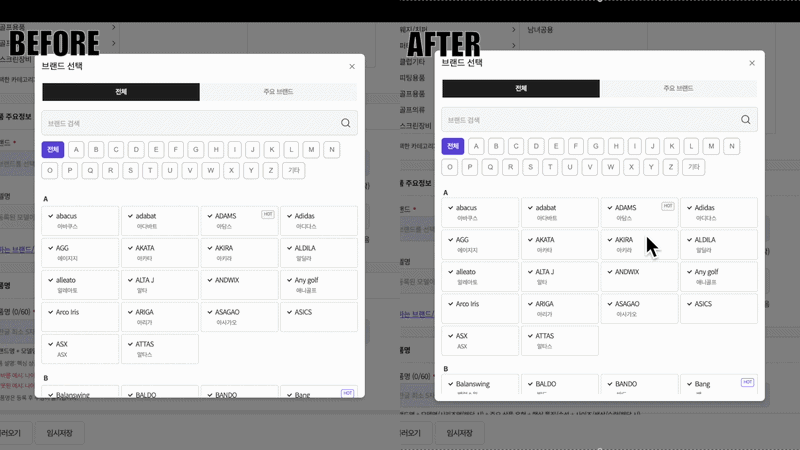
위와 같이 실제 동작을 비교해보면 그 차이가 확실히 드러나는데요. 지금부터 어떻게 성능개선을 했는지 기록해보려고 합니다.
1. 구조 파악하기
본격적으로 원인을 찾기 전에, 브랜드 모달의 구조부터 정리했습니다.
ProductBrandModalInput ← 브랜드 섹션 진입점
└── BrandModal
└── Shared.Tabs
├── ProductBrandModalBody (type="major") ← 주요 브랜드
└── ProductBrandModalBody (type="alphabet") ← 전체 브랜드
└── AlphabetSort
├── SearchInput (sticky)
├── AlphabetFilter (sticky)
└── 알파벳 그룹 × Grid × ProductBrandRadio (수백 개)
여기서 눈여겨볼 부분이 두 가지 있었어요.
첫째, 공통 모달 컴포넌트인 ModalBase가 isOpen이 false일 때 return null을 반환하는 구조였습니다. 즉, 모달이 닫히면 자식 컴포넌트가 완전히 unmount되고, 다시 열릴 때 처음부터 mount된다는 뜻이에요.
둘째, 전체 브랜드 탭에서는 수백 개의 ProductBrandRadio 컴포넌트가 한 번에 DOM에 렌더링되고 있었습니다. 화면에 보이는 건 15~20개 정도뿐이지만, 스크롤 아래쪽 요소들까지 전부 렌더링되고 있었어요.
이 두 가지 특성이 성능 문제와 직결되어 있었는데, 어떻게 연결되는지는 이어서 살펴보겠습니다.
2. 첫 번째 가설 — API 재호출이 문제일 것이다
문제
처음 의심한 건 네트워크였어요. 앞서 구조에서 봤듯 모달이 닫히면 자식이 unmount되고, 다시 열 때마다 mount됩니다. 이 과정에서 useProductBrandsQuery가 매번 재실행되는 구조였어요.
당시 훅은 이렇게 구현되어 있었습니다.
export function useProductBrandsQuery() {
return useQuery({
queryKey: productBrandQueryKey.brands,
queryFn: productBrandApi.getBrands,
// staleTime 미설정 → 프로젝트 기본값(30초) 적용
});
}
우리 프로젝트는 QueryClient의 defaultOptions에 staleTime: 30초를 설정해두고 있어요. 따라서 캐시된 브랜드 데이터도 30초가 지나면 stale로 간주되고, 그 이후 모달을 다시 열 때 백그라운드 refetch가 발생합니다. 브랜드 목록처럼 거의 변하지 않는 데이터의 특성을 고려하면, 30초는 다소 짧은 주기였어요.
게다가 페이지에 처음 진입한 시점에는 캐시조차 없기 때문에, 첫 모달 오픈 시에는 API 응답이 끝나야 브랜드 목록이 표시됩니다. 이 과정이 유저의 "느리다"는 체감을 만들어내고 있다고 생각했어요.
해결
두 가지 수정을 적용했습니다.
① staleTime: Infinity 추가 — 브랜드 목록은 세션 중에 변경되지 않는 데이터이므로, 영구 캐시로 설정해도 안전합니다. 새 브랜드 추가는 관리자 작업이고, 유저가 세션 중에 해당 변경을 실시간으로 반영받아야 하는 요구사항도 없었어요.
const BRAND_STALE_TIME = Infinity;
export function useProductBrandsQuery() {
return useQuery({
queryKey: productBrandQueryKey.brands,
queryFn: fetchProductBrands,
staleTime: BRAND_STALE_TIME,
});
}
② prefetch 훅 추가 — 브랜드 선택은 필수 단계이므로, 모달을 열기 전에 상위 컴포넌트가 mount되는 시점에 미리 데이터를 가져오도록 했습니다.
export function usePrefetchProductBrandsQuery() {
const queryClient = useQueryClient();
useEffect(() => {
queryClient.prefetchQuery({
queryKey: productBrandQueryKey.brands,
queryFn: fetchProductBrands,
});
}, [queryClient]);
}
export const ProductBrandModalInput = ({ formProps, ... }) => {
usePrefetchProductBrandsQuery(); // 페이지 진입 시점에 prefetch
const [isOpen, { on, off }] = useBoolean();
// ...
};
가설이 맞았다면 이 수정만으로도 모달 오픈이 충분히 빨라져야 했어요. 그런데 수정 후 체감 속도는 여전히 한 박자 느린 상태였습니다. "어? 왜 그대로지?" 싶어서 제대로 측정해보기로 했어요.
3. 측정 — 제한적인 1차 개선효과
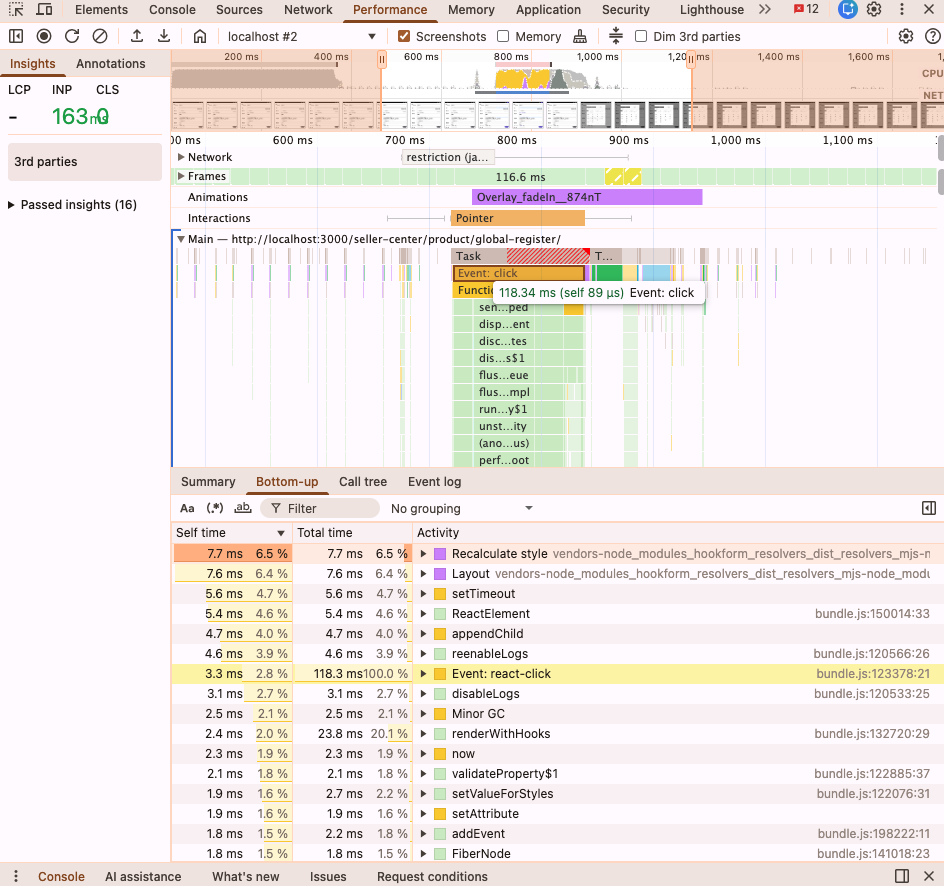
Chrome DevTools의 Performance 탭으로 모달 오픈 시점을 녹화했습니다.
초기 측정 (staleTime, prefetch 미적용):
Chrome DevTools Performance 탭을 녹화한 결과, 클릭 이벤트는 약 459ms, INP는 529ms가 측정됐습니다.
그 다음 staleTime: Infinity와 prefetch 훅을 추가한 후 다시 측정해봤어요.
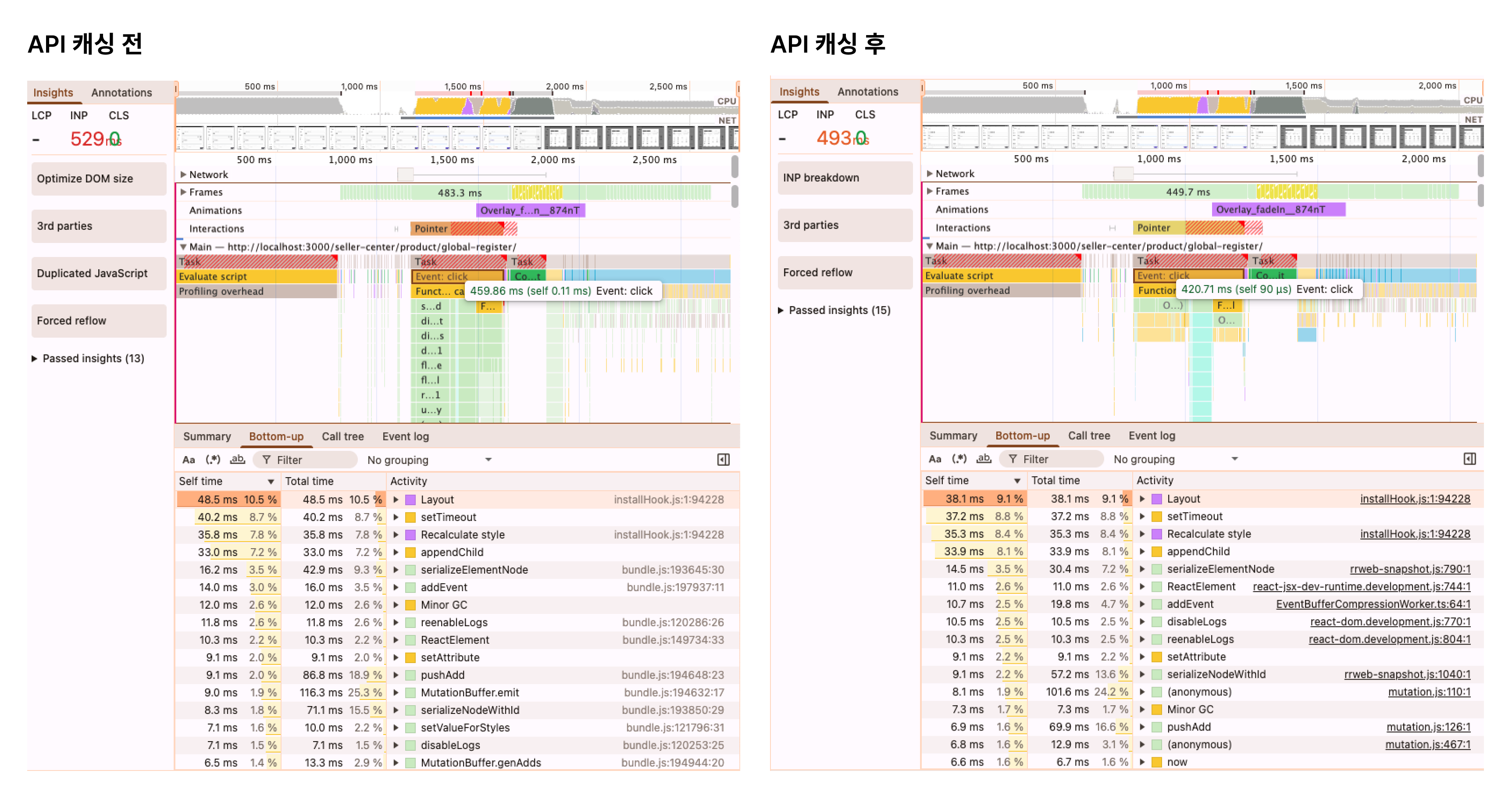
결과:
INP: 529ms → 493ms (-36ms, -6.8%)
클릭 이벤트: 459ms → 421ms (-38ms, -8.3%)
"어? 이게 전부야?" 싶을 정도로 개선폭이 작았어요. 그런데 클릭 이벤트 내부를 분해해보니, 브랜드 API 호출이 보이지 않았어요. Network 탭을 함께 확인해도 마찬가지였습니다. 클릭 시점 전후로 브랜드 관련 네트워크 요청이 전혀 잡히지 않고 있었어요.
421ms 중 API 호출 시간은 0ms였고, 렌더링 파이프라인이 거의 전부를 차지하고 있었어요.
처음엔 당황스러웠습니다. "그럼 내가 고친 건 아무 의미가 없었나?" 싶었거든요. 하지만 찬찬히 생각해보니, 트레이스에 API 호출이 잡히지 않는 건 합리적인 결과였어요.
TanStack Query의 background refetch는 비동기로 실행됩니다. 즉, 모달 오픈 → 캐시된 데이터로 즉시 렌더 → 이후 백그라운드에서 refetch 순서로 진행되기 때문에, 클릭 이벤트의 동기 경로 안에는 API 호출이 포함되지 않아요. 게다가 트레이스를 녹화하던 시점엔 이미 페이지에 진입한 직후였기 때문에, 브랜드 데이터가 이미 캐시에 올라가 있는 상태였습니다.
결국 트레이스만 놓고 판단하자면, 클릭 이벤트의 421ms는 순수하게 렌더링 비용이었던 거예요.
4. 하지만 API 문제는 실제로 존재했다
그렇다면 첫 번째 가설은 그냥 틀렸던 걸까요? 정리하다 보니 그렇지 않다는 걸 알게 됐습니다.
트레이스에 잡히지 않았던 건 녹화 시점에 이미 캐시가 확보된 상태였기 때문이지, staleTime = 0 상태에서 발생할 수 있는 문제 자체가 사라진 건 아니었어요. 실제로 두 가지 시나리오에서는 API가 여전히 병목이 될 수 있었습니다.
시나리오 1: 페이지 첫 진입 (캐시 없음)
페이지에 처음 진입해서 바로 모달을 열면 캐시가 없기 때문에 API 응답을 기다려야 합니다. 이 수백 ms의 대기가 바로 "처음 여는 게 느리다"는 체감의 원인이 되고 있었어요. prefetch 훅을 추가한 덕분에, 페이지 진입 시점에 이미 브랜드 데이터를 요청하고 있으니 유저가 실제로 모달을 열 즈음에는 캐시가 확보되어 있어 대기 없이 즉시 렌더링됩니다.
시나리오 2: 탭 전환 후 복귀 시 불필요한 refetch
TanStack Query는 window focus 이벤트를 감지해서, 캐시가 stale인 경우 백그라운드에서 refetch를 실행합니다. staleTime = 0인 상태에선 탭을 잠시 떠났다가 돌아올 때마다 캐시가 stale로 간주되어 불필요한 API 호출이 반복적으로 발생하게 돼요. 렌더링 자체는 이전 데이터로 빠르게 되지만, 매번 네트워크 요청이 일어나는 건 좋지 않은 상태였습니다. staleTime: Infinity를 설정하면서 이 불필요한 refetch도 함께 차단할 수 있었어요.
결국 첫 번째 가설은 "트레이스에서 재현되지 않았다"는 이유로 폐기할 수 있는 문제가 아니었습니다. 트레이스에 보이지 않는다고 없는 문제가 아니라는 것, 이 점이 이번 작업에서 얻은 첫 번째 교훈이었어요.
5. 트레이스 속 진짜 범인 — rrweb과 DOM 노드 수
첫 번째 가설이 실제로 유효했다는 걸 확인한 뒤에도, 클릭 이벤트의 421ms는 별도로 해결해야 할 독립된 문제였습니다. 이건 명백히 렌더링 비용이었으니까요.
트레이스에서 가장 눈에 띈 건 rrwebWrapped 항목이었어요. 처음 보는 이름이라 파고들어봤습니다.
rrweb은 Sentry Session Replay의 내부 구현체입니다.
저희 서비스는 Sentry를 쓰고 있고, 그중에서도 Session Replay 기능을 활성화해 놓은 상태였어요. Session Replay는 유저의 화면 상호작용을 녹화해서 버그가 발생했을 때 그 순간의 UI 상태를 그대로 재현해주는 기능인데, 내부적으로는 rrweb이라는 라이브러리를 사용합니다.
rrweb은 DOM의 모든 변화를 실시간으로 직렬화해서 녹화 데이터로 저장해요. 일반적인 Sentry 에러 트래킹은 에러가 발생했을 때만 데이터를 수집하지만, Session Replay는 DOM mutation이 발생할 때마다 동작합니다. 그래서 대규모 DOM이 한 번에 생성되는 상황에서는 직렬화 비용이 선형적으로 증가해요.
브랜드 모달을 여는 동작은 수백 개의 브랜드 아이템이 한꺼번에 mount되는 상황이었고, 이는 정확히 "대규모 DOM 한 번에 생성"에 해당하는 시나리오였습니다. 따라서 rrweb의 DOM 직렬화 비용이 상당했어요.
여기서 중요한 인사이트 하나를 얻었습니다.
rrweb 오버헤드를 직접 줄이는 가장 효과적인 방법은 DOM 노드 수 자체를 줄이는 것이다.
Session Replay 옵션을 끄거나 rrweb의 동작 방식을 건드리지 않아도, 직렬화할 DOM 노드가 적으면 자연스럽게 비용이 줄어듭니다. 그리고 DOM 노드 수를 줄이는 건 rrweb뿐 아니라 Layout 계산, CSS 스타일 계산, React 렌더링 비용까지 함께 줄여주는 작업이에요. 브라우저의 렌더링 파이프라인 전체가 DOM 노드 수에 비례하는 비용을 가지니까요.
실제로 트레이스에서 병목으로 잡히는 항목들이 전부 DOM 크기에 비례하는 것들이었습니다. 그래서 해결 방향은 자연스럽게 한 곳으로 좁혀졌어요. 가상화(Virtualization) 였습니다.
6. 가상화 적용
화면에 보이는 브랜드는 15~20개뿐입니다. 그런데 수백 개를 전부 DOM에 올려놓고 있다면, 그 차이만큼이 순수한 낭비인 셈이에요. 가상화는 이 낭비를 해소하기 위한 기법입니다. 뷰포트에 보이는 것만 실제 DOM에 렌더링하고, 나머지는 가상의 공간으로만 유지하는 방식이에요.
6-1. 라이브러리 선택
프론트엔드에서 가상화를 구현하는 방법은 몇 가지가 있습니다. 각 방법을 비교해보면 이랬어요.

ProductBrandRadio 컴포넌트는 영문명과 한글명을 두 줄로 표시하고 white-space: pre-wrap을 쓰기 때문에, 브랜드 이름의 길이에 따라 실제 DOM 높이가 달라집니다. 고정 높이를 전제하는 react-window로는 대응이 어려웠고, 동적으로 높이를 측정해주는 measureElement API가 있는 @tanstack/react-virtual이 가장 적합했어요.
또한 프로젝트에서 이미 @tanstack/react-query와 @tanstack/react-table을 사용하고 있어서, 같은 생태계의 라이브러리를 도입하는 것이 학습 비용이나 향후 유지보수 측면에서도 유리했습니다.
6-2. 핵심 아이디어 — Grouped Grid에서 Flat Row로
가상화를 적용하면서 가장 까다로웠던 부분은 기존 데이터 구조였습니다. 브랜드 목록은 단순한 flat list가 아니라, 알파벳 헤더와 Grid 레이아웃이 중첩된 구조였거든요.
// 기존 데이터 구조
[
{ alphabet: "A", data: [brandA1, brandA2, brandA3, brandA4, brandA5] },
{ alphabet: "B", data: [brandB1] },
// ...
]UI에서는 알파벳 헤더 아래 브랜드들을 격자(Grid)로 배치합니다. 모바일에서는 2열, PC에서는 4열로 보여주고 있어요.
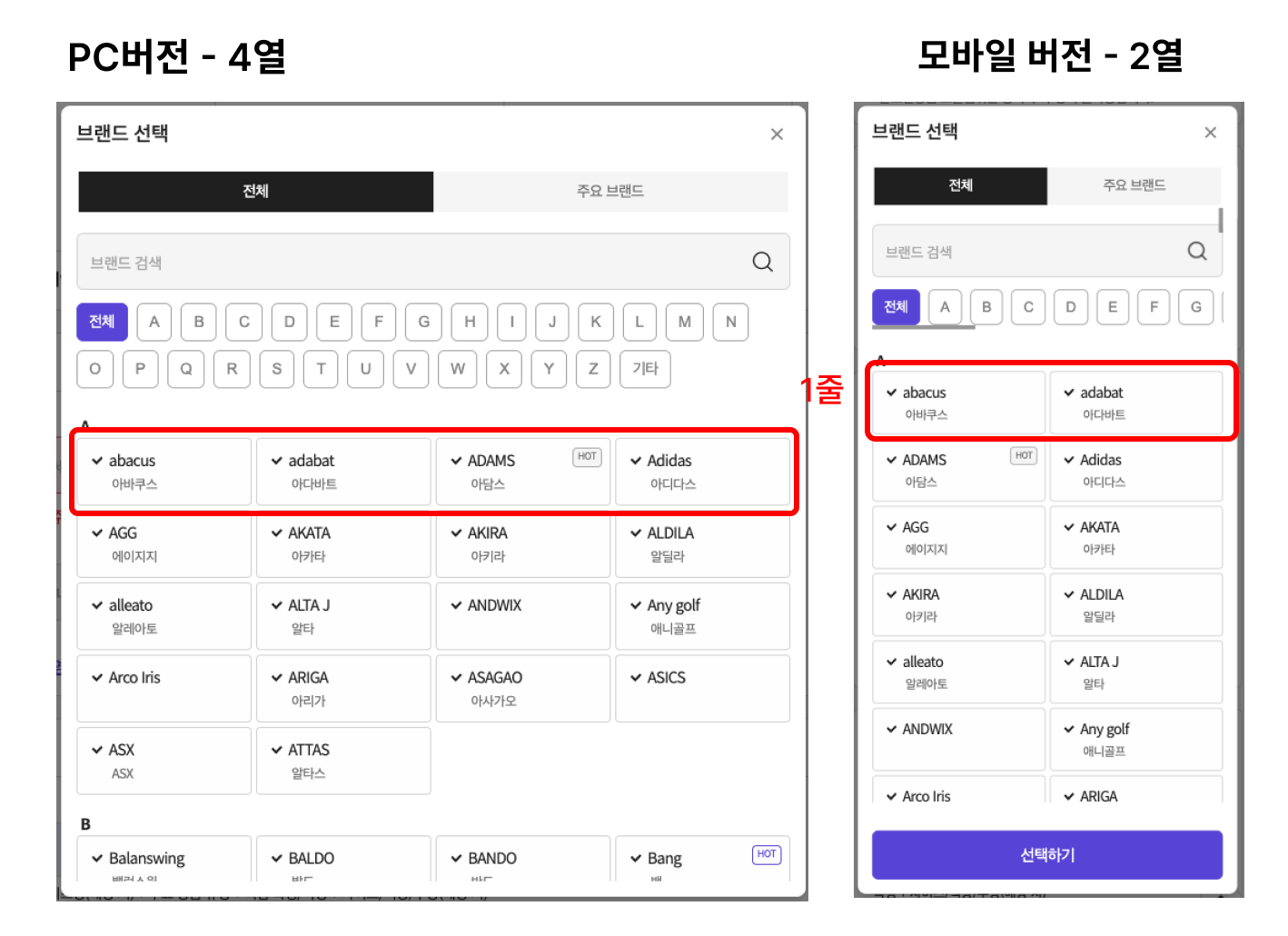
대부분의 가상화 라이브러리는 flat list를 전제로 동작합니다. 한 줄(row)이 곧 하나의 가상화 단위가 되거든요.
그런데 우리 데이터는 중첩 구조라서 한 줄이 무엇인지 명확하지 않아요. "brandA1"이 한 줄인가? 아니면 "brandA1 brandA2"가 한 줄인가? 가상화 라이브러리는 이 구조에서 한 줄의 높이를 어떻게 계산해야 할지 모릅니다.
그래서 택한 방법은 UI에서 보여지는 한 줄을 그대로 데이터 구조로 표현하는 것이었습니다. 헤더 한 줄, 브랜드 한 줄(2열 또는 4열로 묶임)이 각각 하나의 row가 되도록요.
// 각 row는 화면에 보이는 한 줄을 의미
type VirtualRow =
| { type: "header"; alphabet: string } // 알파벳 헤더 한 줄
| { type: "brands"; items: ProductBrand[] }; // 브랜드 한 줄 (최대 columnCount개)변환 로직은 다음과 같습니다.
// 화면 너비에 따라 한 줄에 들어가는 브랜드 개수 결정
// 모바일: 2열, PC: 4열
const columnCount = isPC ? COLUMN_COUNT.PC : COLUMN_COUNT.MOBILE;
const virtualRows = useMemo<VirtualRow[]>(
() =>
(filteredAlphabetBrands ?? [])
// 1. 빈 그룹 제거 (브랜드가 하나도 없는 알파벳은 헤더도 노출하지 않음)
.filter(({ data }) => data.length > 0)
// 2. 각 알파벳 그룹을 [헤더 한 줄, 브랜드 행들...] 형태로 펼침
.flatMap(({ alphabet, data }) => {
// 브랜드들을 columnCount 단위로 묶어서 행 배열 생성
// 예) [A1, A2, A3, A4, A5] → [[A1, A2], [A3, A4], [A5]]
const brandRows: VirtualRow[] = Array.from(
{ length: Math.ceil(data.length / columnCount) },
(_, i) => ({
type: "brands" as const,
items: data.slice(i * columnCount, (i + 1) * columnCount),
})
);
// 헤더 한 줄을 맨 앞에 붙이고 브랜드 행들과 합쳐서 반환
return [{ type: "header" as const, alphabet }, ...brandRows];
}),
[filteredAlphabetBrands, columnCount]
);이렇게 변환하면 원래의 그룹 구조가 아래처럼 펼쳐집니다 (모바일 2열 기준).
[
{ type: "header", alphabet: "A" }, // 1번째 줄: 헤더
{ type: "brands", items: [A1, A2] }, // 2번째 줄: 브랜드 2개
{ type: "brands", items: [A3, A4] }, // 3번째 줄: 브랜드 2개
{ type: "brands", items: [A5] }, // 4번째 줄: 브랜드 1개 (마지막 행은 부족하면 1개)
{ type: "header", alphabet: "B" }, // 5번째 줄: 헤더
{ type: "brands", items: [B1] }, // 6번째 줄: 브랜드 1개
]이제 flat list와 동일한 구조가 되어 가상화 라이브러리에 그대로 넘겨줄 수 있어요. 가상화 라이브러리는 각 row의 높이만 알면 되거든요.
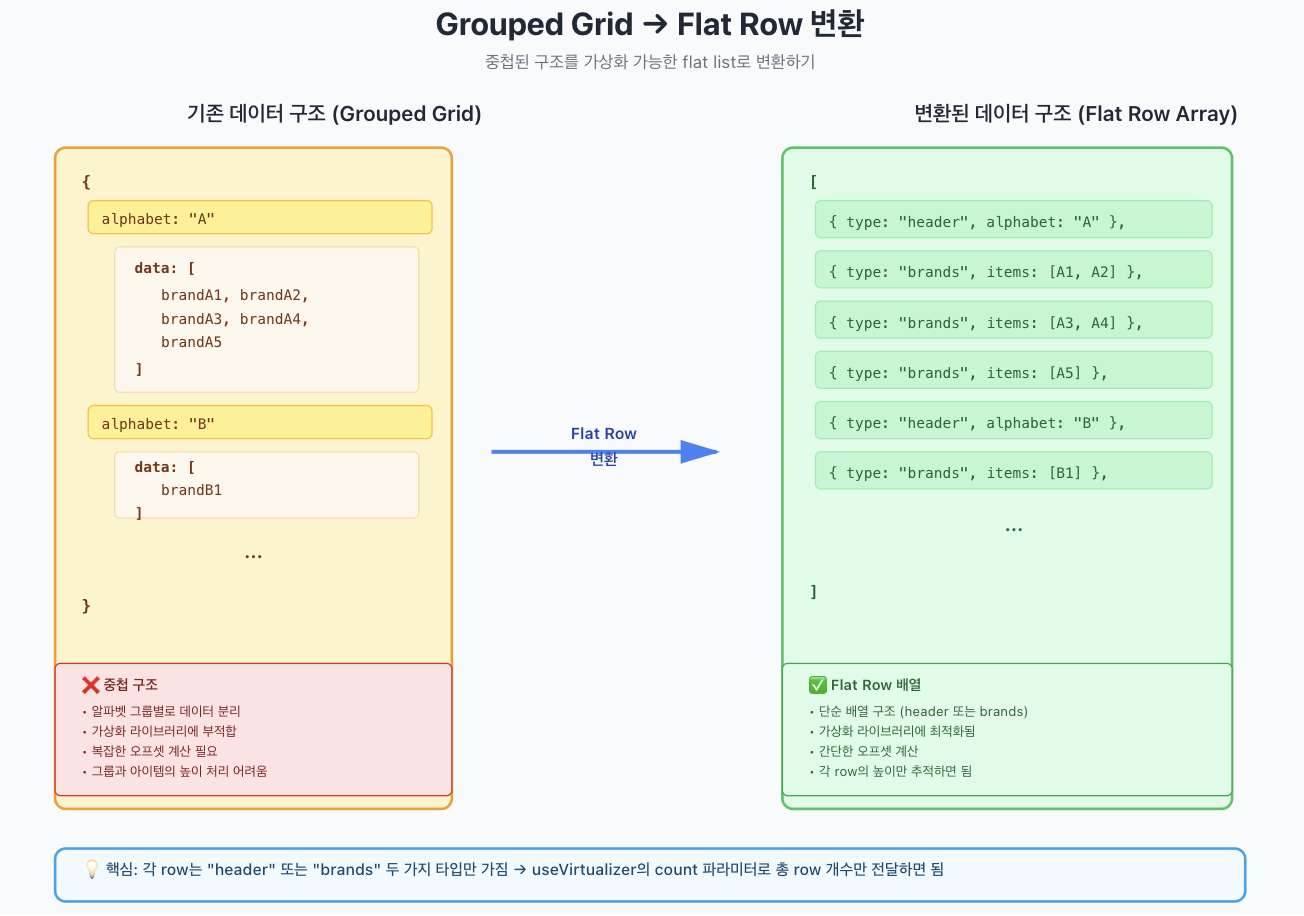
6-3. useVirtualizer 설정
@tanstack/react-virtual의 훅은 이렇게 설정했습니다.
const virtualizer = useVirtualizer({
count: virtualRows.length,
getScrollElement: () => parentRef.current,
estimateSize: i => (virtualRows[i].type === "header" ? 36 : 60),
measureElement: el => el.getBoundingClientRect().height,
overscan: 3,
});
estimateSize는 초기 추정 높이입니다. 헤더는 36px, 브랜드 행은 60px로 설정했어요. 이 값이 정확할 필요는 없고, 빠르게 유사한 높이를 반환하는 용도로만 쓰입니다. measureElement가 실제 DOM 높이를 측정해서 추정값을 보정해주기 때문에, 가변 높이는 그 단계에서 정확히 반영되거든요.
overscan: 3은 뷰포트 바깥 위아래 3행씩 미리 렌더링해서, 빠르게 스크롤할 때 빈 화면이 잠깐 노출되는 것을 방지하는 역할을 합니다.
6-4. 스크롤 컨테이너 구조 변경
구현 중 한 가지 결정해야 했던 부분이 있었습니다. useVirtualizer는 스크롤 이벤트를 감지할 DOM 엘리먼트의 ref를 요구하는데, 기존엔 공통 모달 컴포넌트인 Shared.Modal.Body가 스크롤 컨테이너 역할을 하고 있었거든요.
공통 컴포넌트의 인터페이스를 바꿔서 외부에서 ref를 주입할 수 있도록 하는 방법도 있었지만, 이 컴포넌트는 다른 모달에서도 이미 사용되고 있었기 때문에 영향 범위가 넓은 변경이 될 수 있었어요. 그래서 가상화가 필요한 AlphabetSort 내부에 스크롤 컨테이너 역할을 할 div를 직접 두고, 그 안에서 자체적으로 스크롤을 처리하도록 구조를 변경했습니다.
<div
ref={parentRef}
style={{ overflowY: "auto", height: "65dvh", position: "relative" }}
>
{/* 검색과 알파벳 필터는 sticky로 유지 */}
<div style={{ position: "sticky", top: 0, zIndex: 3, ... }}>
<SearchInput ... />
<AlphabetFilter ... />
</div>
{/* 가상화 컨테이너: 전체 높이를 확보하되 실제 DOM은 보이는 것만 */}
<div style={{ height: virtualizer.getTotalSize(), position: "relative" }}>
{virtualizer.getVirtualItems().map(virtualItem => {
const row = virtualRows[virtualItem.index];
return (
<div
key={virtualItem.key}
data-index={virtualItem.index}
ref={virtualizer.measureElement}
style={{
position: "absolute",
top: 0,
left: 0,
width: "100%",
transform: `translateY(${virtualItem.start}px)`,
}}
>
{row.type === "header" ? (
<b>{row.alphabet.toLocaleUpperCase()}</b>
) : (
<Grid columns={columnCount}>
{row.items.map(brand => (
<ProductBrandRadio key={brand.brandCode} brand={brand} ... />
))}
</Grid>
)}
</div>
);
})}
</div>
</div>
결과적으로 모달 내부에 스크롤 컨테이너가 중첩된 구조가 되어 약간의 복잡성은 추가되었지만, 공통 컴포넌트 인터페이스를 건드리지 않고 로컬한 영향 범위 안에서 가상화를 완료할 수 있었어요. 전체 서비스에 미치는 리스크를 최소화할 수 있었다는 점에서 받아들일 만한 트레이드오프였습니다.
7. 결과
모든 수정을 적용한 뒤 다시 트레이스를 측정했습니다.
결과는 다음과 같습니다.
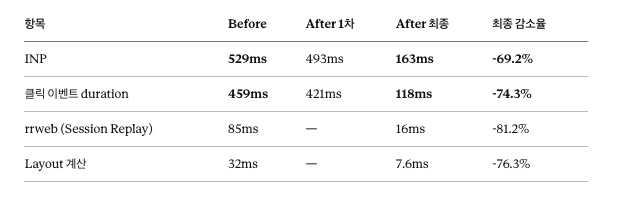
DOM 노드 수도 근본적으로 달라졌어요. 이전에는 모달을 열 때 수백 개의 브랜드 아이템이 한꺼번에 mount됐다면, 가상화 적용 후에는 스크롤 위치와 상관없이 항상 약 30개(overscan 포함)만 유지됩니다. 뷰포트를 벗어난 항목은 DOM에서 제거되기 때문이에요.
그리고 트레이스에는 직접 드러나지 않지만, staleTime: Infinity와 prefetch 적용 덕분에 체감 영역에서 다음 개선도 함께 얻었습니다.
페이지 첫 진입 후 모달 오픈: prefetch 덕분에 대기 없이 즉시 렌더링
탭 전환 후 복귀 시: 불필요한 API refetch 제거
마치며
이 작업을 통해 성능 개선이 얼마나 다층적인 과정인지 느꼈습니다.
초반에 적용한 API 캐싱(staleTime, prefetch)은 합리적인 개선이었지만, 결과는 겨우 -6.8% 였어요. 만약 여기서 "충분하다"고 멈췄다면, 전체 개선폭의 90%를 놓쳤을 겁니다. 차이는 측정에서 나왔습니다. 트레이스를 들여다본 덕분에 API가 아니라 DOM 렌더링이 진짜 병목이라는 걸 알 수 있었거든요.
가상화를 통해 DOM 노드를 줄였을 때의 개선 효과는 예상을 훨씬 넘었습니다. 단순히 React 렌더링만 개선된 게 아니라, rrweb의 직렬화 비용이 -81.2%, Layout 계산이 -76.3% 줄어들었어요. DOM을 최적화하는 것이 브라우저 렌더링 파이프라인 전체에 영향을 미친다는 걸 수치로 확인할 수 있었습니다.
최종적으로 -69.2% 라는 개선율을 얻은 건
API 캐싱으로 첫 진입 경험 개선
DOM 최적화로 렌더링 병목 해결
트레이스 분석으로 진짜 원인 파악
이 세 가지가 함께 작용했기 때문입니다. 하나만으로는 부족했고, 다 함께해야 완성되는 최적화였어요. 성능 개선이 늘 그렇듯, 측정에서 출발해 가설을 세우고, 실험하고, 재측정하는 사이클을 제대로 도는 것이 핵심입니다. 판매자가 상품을 등록할 때 조금 더 매끄러운 경험을 하게 되었다는 점이 이 작업의 가장 의미 있는 결과라고 생각합니다.
긴 글 읽어주셔서 감사합니다.